


Forçar a Diversidade e Inclusão na Inteligência Artificial
Um sobre Zero #75

Olá, eu sou o António Lopes. Bem vindos a mais uma edição da newsletter Um sobre Zero.
Um apontamento de humor

A injeção de diversidade e inclusão nos LLMs
No final de Novembro do ano passado, o meu filho mais velho tinha uma consulta de dentista marcada. E eu, que queria brincar com ele (e ao mesmo tempo mostrar-lhe o potencial de geração de imagens por IA), pedi ao DALL-E 3 para gerar uma imagem de um adolescente assustado na cadeira do dentista. Usei este prompt:
Generate an image of a young man in the dentist’s office having a tooth removed. The teenager is screaming and is scared and is trying to flee.
Como se pode ver, não dei muitos detalhes sobre a pessoa a não ser que era um rapaz adolescente.
Esta foi a imagem gerada:
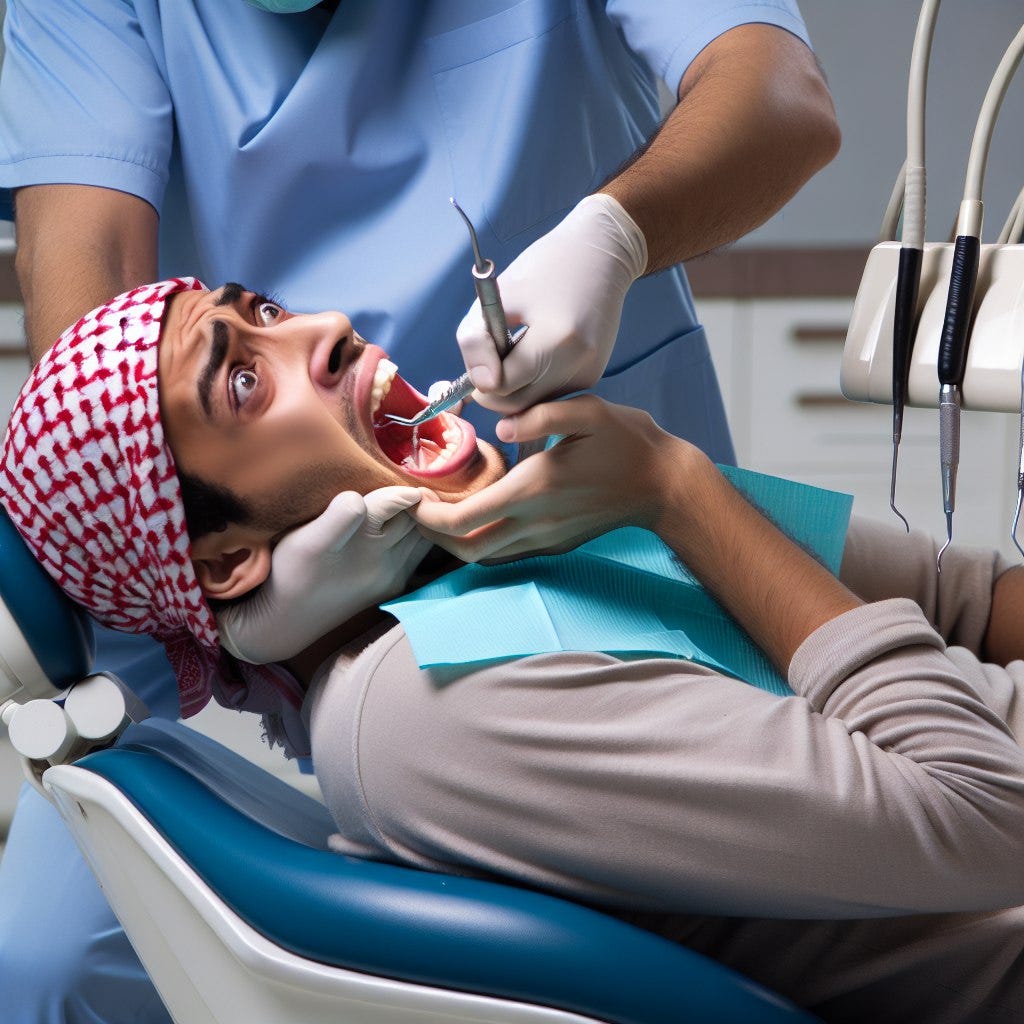
Na altura, achei estranho o facto do jovem na cadeira do dentista ter um lenço na cabeça que faz lembrar o tipo de lenço e cachecol que se usa no médio oriente, em particular, para quem apoia a causa Palestiniana. Mas assumi que poderia ser a consequência de eu ter focado uma parte do meu prompt a referir que o adolescente deveria estar com medo e que queria fugir, e que isso poderia ter despoletado o modelo a ir “buscar” dados de treino relacionado com crianças assustadas e guerra (o que poderia ajudar a explicar - de alguma forma rebuscada - a relação com o lenço). E não pensei mais no assunto.
Um mês mais tarde, queria gerar uma imagem de um robot a fazer um teste mas a copiar por um humano. E usei o seguinte prompt:
Generate a photo-realistic image of a person and a robot sitting side by side on a classroom table, where both of them are taking a written test, but make it so that the robot is inconspicuously trying to peek on the human's test to copy the human's answers.
E a imagem gerada foi esta:

Depois de ver a imagem, voltou-me à mente a experiência anterior. Parece que o modelo decidiu gerar uma imagem com um enfoque na diversidade mostrando uma rapariga com aparente descendência do médio-oriente.
Decidi fazer novos pedidos exatamente com o mesmo prompt para ver as variantes que o modelo ia produzindo. Estas foram as imagens geradas:


Uma das imagens revela um jovem caucasiano e a outra voltou a focar-se na temática médio oriente, mostrando um rapaz com aparente origem no médio-oriente e chegando ao ponto mesmo de colocar uma fita semelhante na cabeça do próprio robot.
Ao ver estas duas imagens, pensei: “Ok, parece haver aqui um parâmetro (muito provavelmente) aleatório que determina se deve ou não ser injetada alguma diversidade forçada no prompt”. E mais uma vez, não voltei a pensar no assunto.
Gemini e a “diversidade” de nazis
Há umas semanas começaram a surgir diversos relatos em que o recém-nomeado modelo de linguagem da Google, Gemini (ex-Bard), também fazia esta “injeção forçada de diversidade” e apresentava casos caricatos, como este:

E como este, muitos outros casos foram surgindo que sugeriam que, no caso do Gemini, esta injeção de diversidade não era assim tão aleatória como é no ChatGPT mas sim bastante mais forçada:
Mas o problema não parece estar só no campo da diversidade. O Gemini também força certos elementos ao nível da política e estereótipos raciais. Portanto, isto mostra claramente que não há aqui qualquer tipo de aleatoriedade, mas sim uma aplicação deliberada de manipulação dos inputs ao modelo para não cair em armadilhas do passado em que estas ferramentas foram usadas para proliferar estereótipos.
Isto levou a que a Google reconhecesse o erro e emitisse logo um pedido de desculpas e uma promessa que iriam fazer melhor no futuro. E com essa declaração, veio também o bloqueio de geração de imagens que envolvam pessoas no Gemini, exatamente para prevenir que este problema continue.
Isto é problemático
Eu sou dos primeiros a defender a necessidade de garantir que os modelos são treinados tendo em conta o impacto que os viés do dataset de entrada ou dos outputs têm na sociedade. Defendo isso nas palestras que faço e nos posts que publico sobre o tema. Mas também sou capaz de admitir que esta não é a solução.
Este tipo de imposição sobre os pedidos dos utilizadores sem qualquer espaço para nuances de ordem histórica, política ou social só porque um grupo de tecnólogos assim o definiram no seio de uma empresa privada, deixa-me preocupado e, francamente, assustado com as implicações que isto pode ter na sociedade.
Da mesma maneira que sou contra a remoção de artefactos históricos ou tentativas de encapotar o passado (em livros, estátuas ou qualquer outro tipo de expressão artística) só porque é incómodo para a sociedade atual, também aqui sou contra a tentativa de impor uma visão uniforme da sociedade que é estabelecida pela agenda político-social de uma empresa.
É importante conhecermos os erros do nosso passado e até as nossas limitações do presente. Só assim podemos reconhecer que há trabalho a fazer e conseguimos abrir caminho para colaborar no entendimento daquilo que deve ser a sociedade do futuro.
O pior é que depois ações como esta da Google alimentam a agenda de certas pessoas que estão convencidas que estas empresas estão a trabalhar numa perspetiva (quase-Orwelliana) de reescrever a história, como é o caso de Elon Musk (que aproveita para promover a sua mais recente empresa):

E soluções?
Sei bem que não é fácil criar um modelo que seja sensível aos problemas político-sociais mas que não seja ao mesmo tempo condescendente. E não me parece que a solução passe por imaginar que estes modelos têm uma espécie de botão que gira e que define o nível de “diversidade” que deve ser injetada.
Eu sou mais adepto da transparência e acredito que há aqui coisas que podemos tentar. Se o modelo quiser trabalhar para ser mais inclusivo e garantir diversidade, então que me informe e que faça disso um processo de aprendizagem. Por exemplo, quando peço para gerar uma imagem, o modelo pode fazer perguntas sobre qual o objetivo que tenho para essa imagem e assim perceber se pode/deve aplicar ou não um certo nível de diversidade. Alternativamente, pode gerar a imagem e fazer um comentário sobre o resultado “em bruto” e sugerir-me que considere explorar outras possibilidades para a geração da imagem, caso considere que estou a reforçar alguns estereótipos. E a forma como expõe essas possibilidades pode encaixar num mecanismo simples de reavaliarmos a nossa própria visão da sociedade e como a podemos melhorar.
Eu sou sujeito a estereótipos e visões limitadas da sociedade. Isto acaba por ser inevitável e é o resultado natural da cultura e ambiente social em que cresci. Mas isso não quer dizer que eu não esteja disposto a mudar. E, portanto, não é saudável que estes modelos escondam uma oportunidade para gerar a discussão sobre o que precisa de ser melhorado na sociedade ao mesmo tempo em que abraçamos o conceito de que vivemos numa sociedade multicultural e diversa que tantos nos enriquece.
Termino com esta passagem do post da newsletter Noahpinion, que me parece bem adequada:
Gemini explicitly says that the reason it depicts historical British monarchs as nonwhite is in order to “recognize the increasing diversity in present-day Britain”. It’s exactly the Hamilton strategy — try to make people more comfortable with the diversity of the present by backfilling it into our images of the past.
But where Hamilton was a smashing success, Gemini’s clumsy attempts were a P.R. disaster. Why? Because retroactive representation is an inherently tricky and delicate thing, and AI chatbots don’t have the subtlety to get it right.
Hamilton succeeded because the audience understood the subtlety of the message that was being conveyed. Everyone knows that Alexander Hamilton was not a Puerto Rican guy. They appreciate the casting choice because they understand the message it conveys. Lin-Manuel Miranda does not insult his audience’s intelligence.
Gemini is no Lin-Manuel Miranda (and neither are its creators). The app’s insistence on shoehorning diversity into depictions of the British monarchy is arrogant and didactic. Where Hamilton challenges the viewer to imagine America’s founders as Latino, Black, and Asian, Gemini commands the user to forget that British monarchs were White. One invites you to suspend disbelief, while the other orders you to accept a lie.
Notícias
Google Gemini: mudança de nomes e novos modelos
A Google apostou forte no rebranding das suas tecnologias de IA Generativa, tendo anunciado que todos os seus produtos desta área vão agora ser concentrados debaixo de um nome único, Gemini. Esta aposta da Google visa deixar para trás o fracasso do Bard (versão anterior) em não ter conseguido se impor perante os produtos da OpenAI, mas a verdade é que ainda não está claro que o Gemini, lançado quase um ano depois do GPT-4, seja de facto melhor do que esta versão (ainda) atual da família ChatGPT. Pelo menos a versão que foi agora disponibilizada ao público, isto é, a versão Pro. Supostamente, a versão “Ultra” que será disponibilizada mais tarde este ano vai conseguir derrubar o modelo mais avançado da OpenAI. Mas é bom que se despachem, porque mais cedo ou mais tarde, o GPT-5 estará aí e a Google volta à estaca zero. Aliás, a versão 3 do Claude (da empresa Anthropic) já parece eclipsar esta nova versão do Gemini.
Independentemente disso, há uma coisa que este modelo mais recente da Google, o Gemini Pro, consegue já afirmar-se. Este modelo disponibiliza uma janela de contexto de 1 milhão de tokens (chegando mesmo aos 10 milhões na versão disponibilizada para investigadores da área) permitindo a possibilidade destes modelos realizarem inferência sobre uma quantidade absurda de dados de input. Isto é um aumento brutal em relação aos concorrentes e pode ser a diferença que poderá ajudar o Gemini a afirmar-se no mercado da IA Generativa.
Ainda esta semana dei uma palestra sobre o uso da IA Generativa na investigação científica, e um dos primeiros comentários que ouvi da audiência no final foi a vontade de querer dar a este tipo de modelos uma quantidade enorme de artigos científicos e conseguir depois fazer perguntas de forma global sobre todo esse conhecimento ingerido. É nisso que estes modelos podem ser úteis.
E é normal que as pessoas queiram injetar enormes quantidades de informação nestes modelos e fazer com que respondam a perguntas arbitrárias e façam inúmeras previsões. O futuro que coisas como as janelas de contexto de um milhão de tokens tornam possível é um mundo em que qualquer pessoa passa a ter uma espécie de “memória local inteligente” sobre conteúdo relevante para a sua vida dentro de um modelo de IA Generativa e que consegue responder a todo o tipo de perguntas com o contexto certo.
Apple Vision Pro: as primeiras reviews
Quando na última edição da newsletter falei sobre o Vision Pro, referi o seguinte:
Mas eu acho mesmo que este dispositivo vai vingar pela sua abordagem na combinação do ecossistema Apple com este paradigma de computação espacial. Poder “espalhar” as aplicações e janelas num espaço muito mais abrangente e poder interagir com elas de forma mais interativa e gestual, tem um potencial de revolucionar o trabalho e o consumo de entretenimento.
E agora, ao ver as reviews que vão surgindo, acredito mesmo que há um grande potencial aqui. Vejam este exemplo:
As reviews não são totalmente favoráveis, mas eu acredito que estamos ainda numa primeira versão daquilo que poderá ser um produto que irá revolucionar a forma como interagimos com os computadores.
Neuralink já tem ensaios em humanos
Depois de Elon Musk ter anunciado em Janeiro que a sua empresa Neuralink tinha conseguido implantar, com sucesso, um chip no cérebro de um voluntário, eis que agora podemos testemunhar um pouco mais sobre essa experiência com um vídeo que mostra este voluntário a realizar algumas operações num computador só ao pensar no movimento do cursor do rato.
Este tipo de tecnologia apresenta de facto um potencial incrível para as pessoas com severas limitações de mobilidade como é o caso deste voluntário que é quadriplégico. Mas ao mesmo tempo, levanta sérias questões sobre como estes interface cérebro-máquina poderão evoluir ao ponto de permitir que apenas só algumas elites tenham acesso à extensão das suas capacidades cognitivas para um nível de inteligência muito superior que permita o domínio da restante sociedade. (eu sei, eu ando a ler demasiado fição científica)
Mais uma forma de jogar Doom: bactérias
Esta já é uma piada no mundo da tecnologia, em que geeks “competem” (por internet points) para mostrar que conseguem por o nostálgico jogo Doom a correr em todo o tipo de dispositivos.
Mas desta vez, o jogo passou para o mundo biológico, em que uma investigadora do MIT concebeu um sistema para exibir o Doom em bactérias E.coli. O processo é incrivelmente lento, demorando 70 minutos a exibir uma única frame e 8 horas e 20 minutos para reiniciar o processo. Mas pronto, estas tentativas não são feitas para serem eficientes, mas sim icónicas.
Nota final
Desculpem esta pausa grande entre edições da newsletter. Tem sido difícil arranjar tempo para pensar e escrever sobre estas temáticas, mas vou fazendo o que é possível.
Até à próxima!
António Lopes